Data labeling
Data labeling is used to process “raw” logs to extract potential intents and fill them with training phrases. Data labeling will be useful if you have your own data for training. If you don’t have it, but your bot has already been in operation for some time and has acquired dialog data, use intent fine-tuning.
To use data labeling:
-
Navigate to a project and select NLU → Data labeling in the dashboard.
-
If you have already used data labeling, select New set of phrases.
-
Prepare a file with the phrases you want to process.
- File requirements: TXT format, UTF-8 encoding.
- Upload up to 10,000 phrases.
- Place each phrase on a separate line.
- Shorten phrases longer than 500 characters, or they will be deleted.
-
Attach your file.
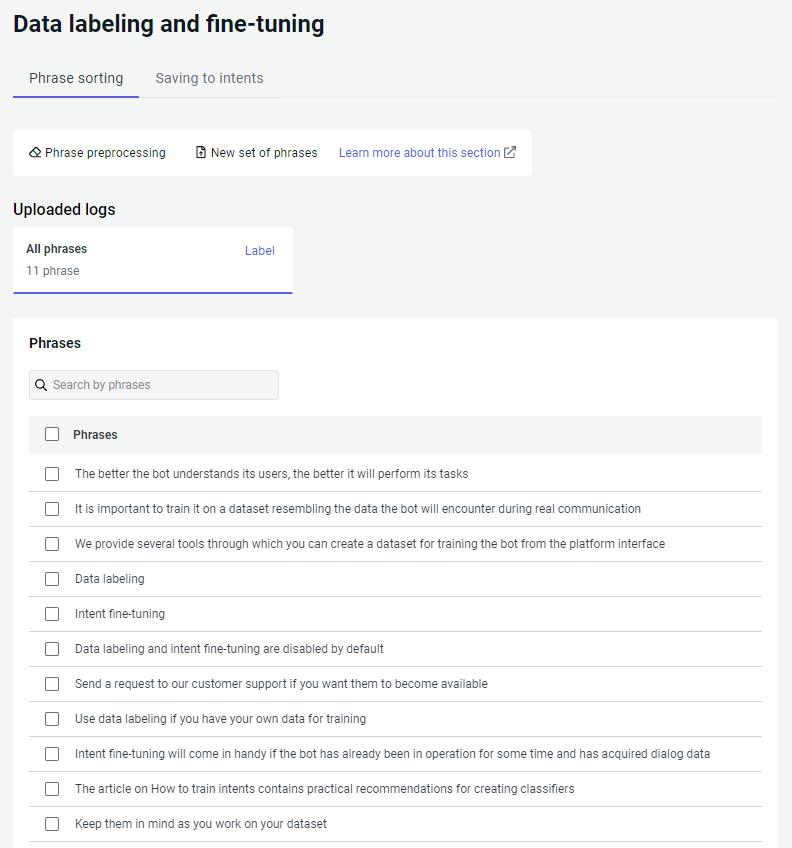
After your file is uploaded, the phrases will appear in the All phrases section.
To fill new and existing intents with uploaded phrases:
Phrase preprocessing
To sort the phrases into intents more easily, it is necessary to preprocess them:
-
Go to the Phrase sorting tab → Phrase preprocessing.
-
Set the parameters:
- Delete special characters — delete all characters except letters and numbers.
- Delete short phrases — delete all phrases shorter than the specified number of characters including spaces.
- Delete long phrases — delete all phrases longer than the specified number of characters including spaces.
- Correct typos — correct spelling errors and typos. Enabled by default. Only for Russian and Ukrainian.
- Delete stop words — the stop word dictionary is built into the platform and is only available for Russian.
- Recognize entities —
look for active system and custom entities in phrases.
For example, “tomorrow at 4 p.m.” will be replaced with “tomorrow at
@duckling.time.” - Remove duplicates — after removing duplicates, only one sample of each phrase will remain. Enabled by default. ? > If you want to review duplicates before deleting them, disable this parameter and use labeling by duplicates.
-
Select Process.
Labeling methods
If you process a lot of phrases, labeling methods will help you group them to make it easier to sort phrases into intents. To do this, go to the Phrase sorting tab. In the Uploaded logs section, click Label and select the labeling method.
You can label phrases:
After you have labeled your dataset, sort phrases into intents.
Also, you can sort the phrases into intents manually:
-
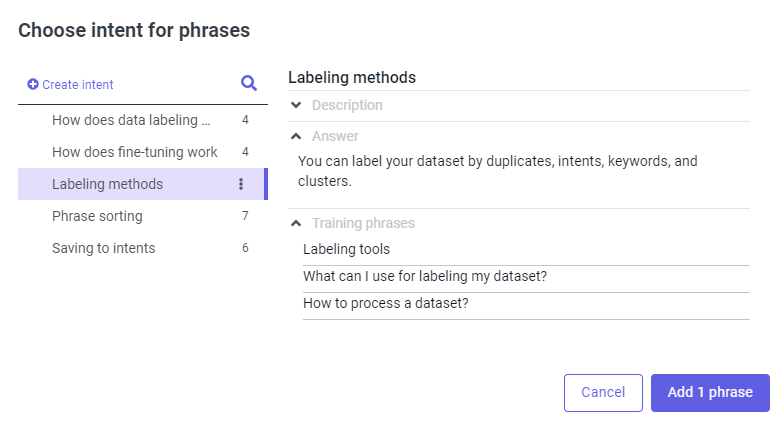
Select one or several phrases and click Add to intents. An intent selection window will open.
-
Select the appropriate intent or create a new one. Then click Add phrase.
-
Go to the Saving to intents tab in the top panel to confirm the changes.
By intents
This labeling method allows you to sort phrases into intents that already exist in your project.
Each recognized phrase is assigned a score from 0 to 1. This is the level of confidence that the phrase is actually contained by the intent. To filter phrases by score, use the slider.
By duplicates
This labeling method allows you to find identical phrases in the dataset. If you have removed duplicates during phrase preprocessing, you don’t need to do this.
By keywords
This labeling method allows you to find keywords in phrases and group your dataset by them.
There are two keyword search methods:
- Frequency-based method that uses TF-IDF.
- Syntactic method that uses the UDPipe parser.
Frequency-based method
TF-IDF allows you to estimate how important a word is in the context of a phrase and the whole dataset. The more important a word is for determining the phrase topic in your dataset, the higher the TF-IDF value will be.
The TF-IDF value is a factor of two multipliers:
- TF (term frequency) is the word frequency in the phrase.
- IDF (inverse document frequency) is the number of all phrases in the dataset divided by the number of phrases with the necessary word. The IDF of a word increases if it occurs in a small number of phrases. If a word occurs frequently in all dataset phrases, its IDF is reduced.
Set the parameters:
-
Cast all words to lower case.
tipIf your dataset includes proper nouns, this option may be useful, otherwise London and london will be considered different words. -
Maximum N-gram length — how many words from the phrase can be used to make word combinations. The default value is 2.
-
Maximum skip-gram number — how many consecutive words that make up word combinations can be skipped in a phrase. For example, your dataset contains the phrase Please don’t ever call me again. When labeling, the following word combinations will be made out of this phrase:
Parameter value Result 1 Please don’t call me again
Don’t call again2 Please call me again
Please don’t ever call3 Call me again The default value is 1. It is not recommended to change the value, because the meaning of the phrase may change.
-
Minimum unigram frequency — how many times a word should occur in the dataset to be taken into account in a keyword search. The default value is 10. The recommended value is 6–7 for medium datasets (from 100 to 1,000 phrases) and 7 or higher for large ones (over 1,000 phrases).
-
Minimum N-gram frequency — how many times a word combination should occur in the dataset to be taken into account in a keyword search. The default value is 5. The recommended value is 2–4 for medium datasets (from 100 to 1,000 phrases) and 5 or higher for large ones (over 1,000 phrases).
-
Maximum number of N-grams from a phrase — how many word combinations can be formed from one phrase. The default value is 4. The recommended value is 2–5, or 6–7 for longer phrases.
Syntactic method
This method allows you to find syntactic relations in phrases using the UDPipe parser. It recognizes syntactic relations in phrases and does part-of-speech tagging.
Set the parameters:
-
Language.
cautionThis method is only available for Russian, English and Chinese. -
Cast all words to lower case.
-
Lemmatize keywords. For example, if you enable this option, the voicemail keyword will be found in Don’t leave me voicemails.
-
The predicate in the phrases is mandatory — only phrases with predicates will be selected.
By clusters
This labeling method allows you to find similar phrases in the dataset and combine them into clusters.
There are two сlustering methods:
- Probabilistic method based on the K-means algorithm.
- Hierarchical method (Linkage) based on Ward’s method.
Probabilistic method
The K-means algorithm sorts phrases into a predetermined number of clusters. To use it, you should estimate the number of clusters sufficient for your dataset. The algorithm will form exactly as many clusters as you set and make them as different as possible.
The algorithm iteratively repeats two steps:
- It sorts phrases from your dataset into clusters.
- It recalculates cluster centers. When cluster centers no longer change, the algorithm ends.
Set the parameters:
-
Language.
cautionThis method is only available for Russian, English and Chinese. -
Number of clusters — how many groups to create. Review your dataset and estimate how many topics are in it. This will be the approximate number of clusters.
Hierarchical method
The Linkage algorithm is based on Ward’s method and sorts phrases into clusters. You do not need to set the number of clusters: it is determined automatically.
Set the parameters:
-
Language.
cautionThis method is only available for Russian, English and Chinese. -
Threshold value — this parameter sets the maximum possible distance between clusters. Cosine similarity is used for calculation. It can take any value from 0 to 1. The default value is 0.25.
tipThe value of this parameter is inversely proportional to the number of clusters the dataset will be split into. -
Number of phrases for clusterisation — the number of phrases you want to process at one time. This option can be useful when you’re working with large datasets. If you want to process all phrases at once, do not change the parameter value.
Phrase sorting
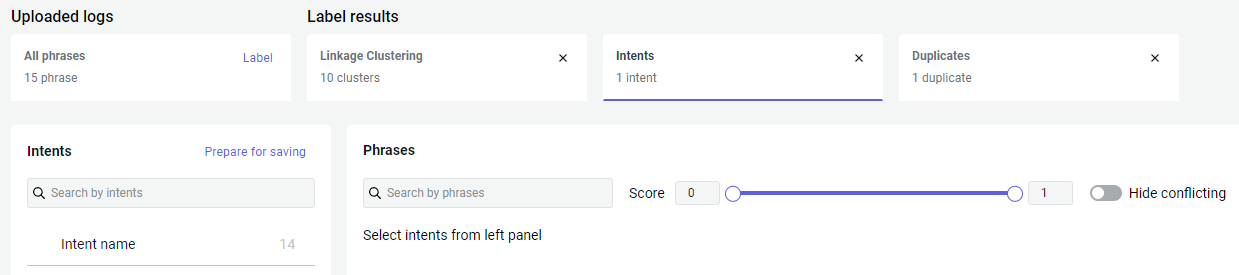
Once you have labeled phrases, you can switch between the labeled content in the Phrase sorting tab → Label results section:
-
Select any labeling result, such as labeling by intents. On the left side, you will find the intents to be populated with the recognized phrases. On the right side, you can see the corresponding recognized phrases.
-
Look through the recognized phrases. With the Hide conflicting option, you can hide phrases assigned to several intents.
tipIt is good practice to examine phrases recognized with a low score: you can find false positives among them. Such phrases should be added to other, more suitable intents. You can also increase the intent thresholds, so that phrases with a low score are recognized less frequently. -
If you are satisfied with the results, go to step 5.
-
If some phrases are not recognized correctly, you can delete them or assign them to the necessary intents manually. To do this, select phrases and click Add to intents. An intent selection window will open.
-
Select the appropriate intent or create a new one. Then click Add phrase.
-
Click Prepare for saving. All recognized phrases will be added to intents. To confirm the changes, go to the Saving to intents tab.
tipSkip this step for the results of labeling by clusters, keywords, and duplicates. After adding phrases to the intents, go straight to the Saving to intents tab.
Saving phrases to intents
-
Select the Saving to intents tab on the top panel. Here you can find all the phrases that you added to the intents while sorting the phrases.
-
Look through the intent tree. You can switch between intents, delete unnecessary phrases, or add them to other intents.
-
Click Save to intents. After that, all the phrases will be saved in the selected intents of the project.
-
In the sidebar, go to NLU → Intents and select Test in the bottom right corner to train the classifier on the new set of phrases.