Как обучать интенты
Через интенты доступны два способа обучить бота понимать естественный язык:
-
Паттерны — формальные правила для сопоставления запросов специал�ьным шаблонам. Например,
{[~ты/~вы] (~любить/нравится) * (спб/питер*/[санкт] *петербург*)}— паттерн, совпадение по которому с высокой вероятностью означает, что бота спрашивают об отношении к Санкт-Петербургу. -
Тренировочные фразы — примеры запросов для обучения классификатора. Например, научить бота распознавать тот же интент можно на таких тренировочных фразах: тебе нравится в спб, ты любишь питер, как ты относишься к санкт-петербургу.
По сравнению с паттернами тренировочные фразы позволяют значительно уменьшить трудозатраты на обучение: не нужно вручную писать правила и пытаться учесть в них все возможные синонимы. Фразы можно добавить в классификатор из внешних файлов с логами, а также разметить фразы прямо из аналитики по диалогам уже после того, как бот был запущен.
С другой стороны, из-за меньшей прозрачности алгоритмов, не основанных на правилах, тренировочные фразы могут быть менее предсказуемы. Если вы используете их для обучения, следует учитывать особенности выбранного классификатора и� придерживаться некоторых правил при составлении обучающей выборки.
Чем различаются алгоритмы классификатора
Требования к обучающей выборке различ�аются в зависимости от того, какой алгоритм классификатора выбран в настройках проекта.
STS
STS (Semantic Textual Similarity) — алгоритм, который сравнивает семантическую близость слов. Он учитывает инверсию, словарные формы слов, их синонимы и другую информацию.
Преимущества STS:
-
Хорошо проявляет себя на небольших выборках: даже если каждый интент содержит всего одну тренировочную фразу, алгоритм будет работать.
-
Позволяет использовать сущности в тренировочных фразах.
-
Не чувствителен к неравномерному распределению фраз по интентам.
-
Различает семантически близкие интенты лучше, чем Classic ML.
-
Обладает самыми гибкими и интерпретируемыми настройками. Используйте расширенные настройки NLU, чтобы адаптировать алгоритм под ваш проект. Например, настройте параметр
synonymMatch, чтобы отрегулировать вес совпадений по синонимам.предупреждениеСлишком тонкие настройки NLU могут уменьшить качество классификации при добавлении новых тренировочных фраз. Кроме того, настройки, адаптированные под один проект, могут не подойти для другого.
Classic ML
Classic ML — стандартный алгоритм машинного обучения для распознавания интентов на основе логистической регрессии.
Преимущества Classic ML:
- Сохраняет хорошую скорость работы при высоких нагрузках на бота.
- Учитывает словарные формы (леммы) и основы слов (стемы).
Deep Learning
Deep Learning — а�лгоритм на основе сверточных нейронных сетей. Использует информацию о семантике слов при формировании гипотез и поэтому в отличие от Classic ML учитывает синонимы.
Преимущества Deep Learning:
- Хорошо проявляет себя на большом наборе данных.
- Различает похожие интенты лучше, чем Classic ML.
Transformer
Transformer — мультиязычный алгоритм. Он оценивает семантическое сходство запроса клиента со всеми тренировочными фразами из интента.
Преимущества Transformer:
- Хорошо проявляет себя на небольших выборках.
- Может распознавать не только языки, которые официально поддерживает JAICP.
- Выполняет классификацию на основе большой языковой модели и использует не просто слова, а информацию о смысловой связи между ними.
- Чувствителен к регистру символов и учитывает знаки препинания.
Сколько нужно тренировочных фраз на интент
Оптимальное число интентов в классификаторе и тренировочных фраз на каждый интент зависит от используемого алгоритма.
- STS — 5–7 тренировочных фраз на интент, но не более 1 000 фраз во всей выборке, чтобы сохранить оптимальную скорость ответа.
- Classic ML — не менее 20 тренировочных фраз на интент. Чем больше выборка, тем точнее будет классификатор.
- Deep Learning — не менее 50 тренировочных фраз на интент. Чем больше выборка, тем точнее будет классификатор.
- Transformer — не менее 10 тренировочных фраз на интент. Чем больше выборка, тем точнее будет классификатор.
Рекомендованная длина тренировочной фразы: 1–10 слов. Длинные фразы плохо подходят для определения интента, поскольку из них сложнее извлечь смысл.
Интенты должны быть обучены равномерно. Например, во всех интентах может быть хотя бы по 20 фраз (Classic ML) или по 50 (Deep Learning).
Как подготовить обучающую выборку
Если содержание интентов пересекается, запросы пользователя могут распознаваться некорректно. Чтобы запросы попадали в нужные интенты, нужно подготовить качественную обучающую выборку без дубликатов, похожих фраз и стоп-слов.
Настроить поиск совпадений
Включите поиск, чтобы избежать дубликатов, а также похожих тренировочных фраз и ответов в интентах:
- Перейдите на главную страницу JAICP и найдите нужный проект в секции Мои проекты.
- Нажмите в карточке проекта → Настройки проекта.
- Найдите Поиск совпадений на вкладке Классификатор и переведите переключатели в активное положение. По умолчанию тренировочные фразы могут совпадать на 50%, а ответы — на 80%.
Поиск совпадений выполняется при вводе новых тренировочных фраз и ответов, а также при их редактировании.
При сохранении фразы происходит классификация. Если у фразы высокий вес со�впадения с другими интентами, то вы получите предупреждение со списком этих интентов.
При сохранении ответ сравнивается с ответами из других интентов по мере Жаккара.
Рассмотрим на примере, как использовать поиск совпадений:
Создайте интент /Хочу купить курс. Заполните его тренировочными фразами и укажите ответ:
- Фразы
- Ответ
- Интересуют эти обучающие курсы
- Мне нужно купить ваш курс
- Я бы хотел приобрести у вас курс
- Хочу купить образовательный курс
Подробная информация о курсе есть на сайте https://example.com/
Нажмите кнопку Тестировать, чтобы обучить классификатор. Теперь содержание интента будет учитываться при поиске совпадений в други�х интентах.
После этого создайте интент /Хочу оформить возврат и заполните его.
По умолчанию фразы могут совпадать на 50%, а ответы — на 80%. Если превысить эти значения, появятся предупреждения:
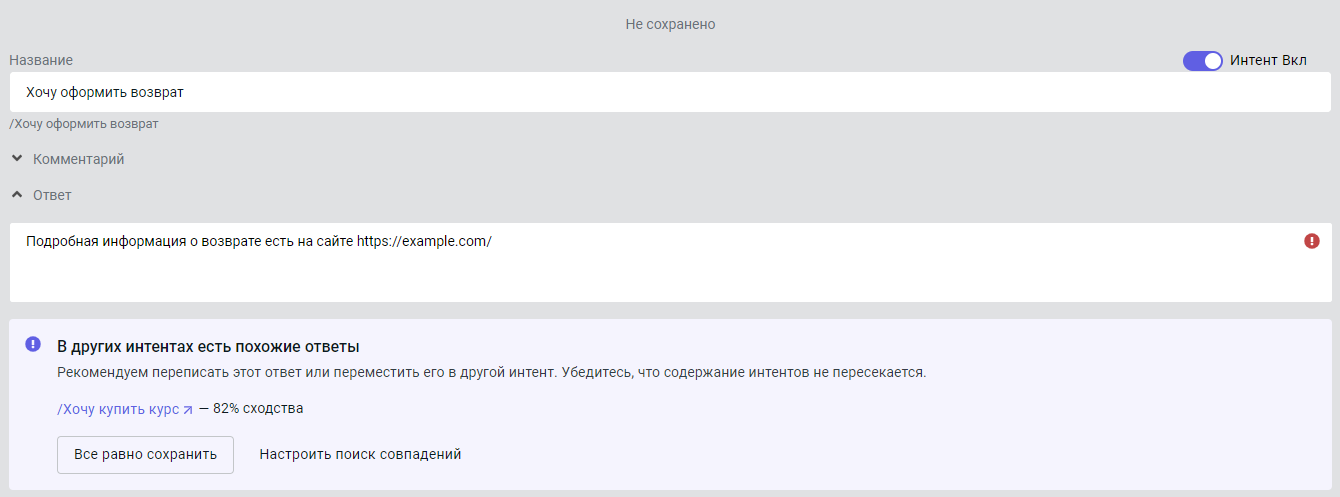
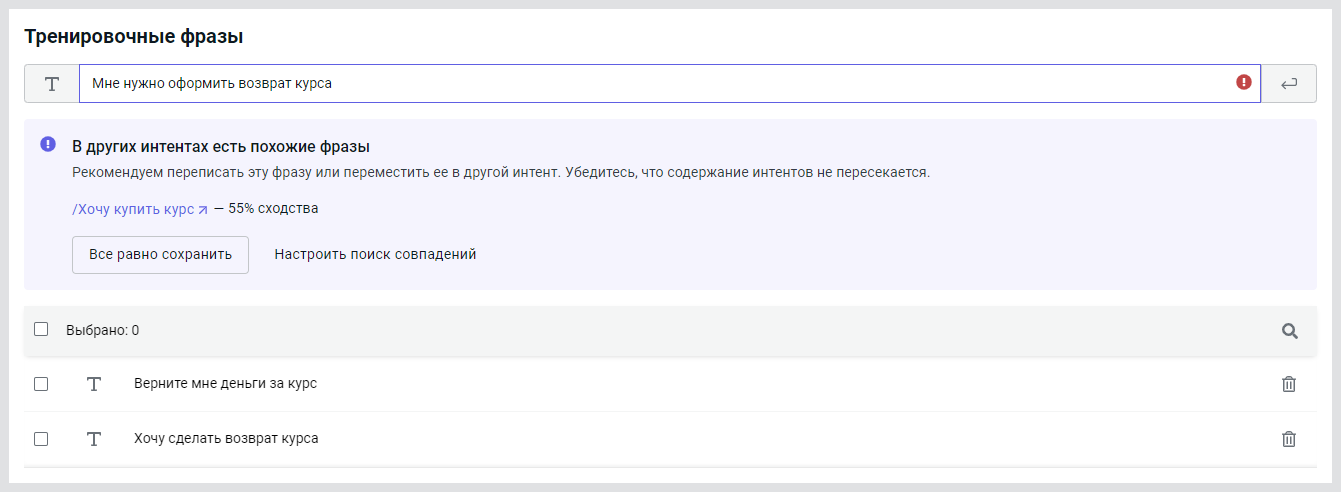
Вы можете:
- Все равно сохранить — сохранить фразы и ответы, несмотря на предупреждение классификатора. Это может привести к ухудшению выборки и пересечению интентов.
- Настроить поиск совпадений — скорректировать настройки классификатора и подобрать оптимальные значения для вашего проекта.
Удалять дубликаты
Алгоритмы Classic ML и Deep Learning чувствительны к дубликатам тренировочных фраз в интент�ах. Вы можете убедиться в этом следующим образом:
- Создайте новый проект, в настройках проекта выберите классификатор Deep Learning.
- Перейдите в меню NLU → Интенты и выберите интент привет. В нем одна тренировочная фраза привет.
- Нажмите Тестировать и введите запрос с похожим смыслом, например всем привет.
- Закройте тестовый виджет, добавьте в интент еще одну тренировочную фразу привет и повторите шаг 3.
После того как вы добавили дубликат, вес совпадения одного и того же запроса увеличился.
Алгоритмы STS и Transformer вычисляют семантическую близость запроса с каждой тренировочной фразой по отдельности. Если вы проделаете тот же эксперимент с проектом на STS или Transformer, то убедитесь, что они нечувствительны к дубликатам и не добавляют вес совпадения интентам с дублированными фразами. Однако лучше избегать их.
Избегать слишком похожих фраз
При формировании выборки важно избегать не только фраз, полностью совпадающих друг с другом, но и различающихся только одним-двумя словами или порядком слов.
- Хороший набор фраз
- Плохой набор фраз
- возможно ли запланировать встречу в банке
- как записаться к менеджеру в отделение
- как записаться на визит к специалисту банка в сочи
- как можно записаться на визит в банк
- могу ли я записаться на посещение отделения
- можно встречу в банке назначить на 4 февраля
- возможно ли запланировать встречу в банке
- встречу в банке можно запланировать
- запланировать встречу в банке на 13 ноября можно
- можно встречу в банке запланировать на 29 апреля
- можно встречу в банке запланировать на 4 февраля
- можно ли встречу в банке запланировать
Фразы из плохого набора состоят из одних и тех же слов и выражают интент только одним способом. Если обучить интент на таких фразах, возникнет проблема переобучения: интент будет хорошо срабатывать только на фразы в такой же формулировке и плохо срабатывать на все остальные.
Чистить стоп-слова
Из тренировочных фраз полезно удалять стоп-слова — высокочастотные неспециализированные слова, которые могут встретиться в запросах на любую тему.
Избегайте неравномерного распределения стоп-слов по интентам. В таком случае типична ситуация, когда на запрос со стоп-словами срабатывает неправильный интент с такими же стоп-словами в обучающей выборке, а правильный интент без них имеет меньший вес.
Часто встречающиеся группы стоп-слов:
- Приветствия и прощания: здравствуйте, пока
- Слова просьбы и благодарности: пожалуйста, спасибо
- Модальные слова: можно, хочу
- Целые фразовые комплексы: у меня вопрос, я хотела бы уточнить
Вы можете взять готовые словари стоп-слов (например, из одного из репозиториев проекта stopwords-iso)
и расширить их словами, специфичными для вашего набора данных.